
The Next Trillion Dollar Wave - AI Narrative in Crypto: Who Are the Top Players?
Dec 12, 2024 21:40
Industry Insights
More
The Next Trillion Dollar Wave - AI Narrative in Crypto: Who Are the Top Players?
Dec 12, 2024 21:40
VC
The Great Crypto Betrayal: VCs Fight Back Against Zombie Projects
Oct 10, 2024 15:54
Video Digest
MoreGigabrain Dialogues
More
Project Deepdive
MoredYdX

A deep dive into the development of dYdX Chain after its launch.
Read MoreBITTENSOR

We dont create algorithms; we just deliver the best ones.
Read MoreEverclear

Everclear is expected to become the standard solution for cross-chain settlement.
Read MoreBASEDAI

An AI project that combines large language models, ZK, homomorphic encryption, and meme coins.
Read More
TechFlow: Sunny and Min
Gensyn: Ben Fielding, Cofounder
"Our aim isn't to monopolize the machine learning stack but to position Gensyn as a protocol optimizing compute resource usage, just above electricity, to significantly enhance humanity's computational efficiency."
-- Ben Fielding, Cofounder at Gensyn

In January 2024, OpenAI CEO Sam stated that the two most important "currencies" of the future will be compute and energy.
However, in the era of AI, compute often becomes a monopolized resource by large corporations, especially in the field of AGI (Artificial General Intelligence) models. This monopoly inevitably triggers anti-monopoly forces, leading to the emergence of Decentralized AI.
The venture capital firm a16z has articulated in an article how blockchain, an permissionless component, can create a marketplace for buyers and sellers of compute (or any other type of digital resource, such as data or algorithms). This market operates globally without the need for intermediaries, and the project described is Gensyn.
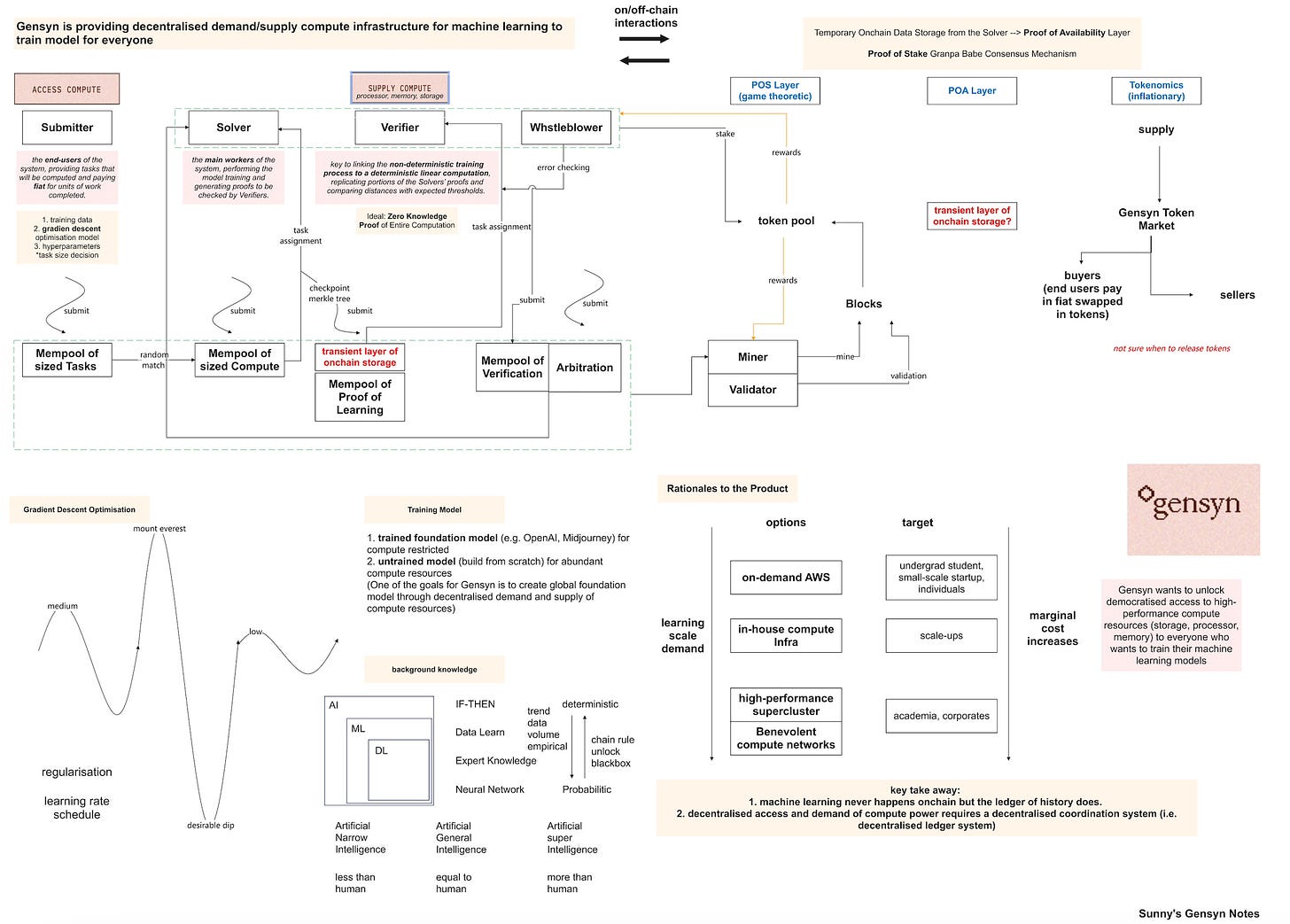
Gensyn is a decentralized deep learning compute protocol designed to be the foundational layer for machine learning computations. It facilitates the distribution and rewarding of machine learning tasks through smart contracts, rapidly enhancing the learning capabilities of AI models and reducing the costs of deep learning training.
Gensyn connects developers (anyone capable of training machine learning models) with solvers (individuals wanting to train machine learning models using their own equipment). By leveraging idle, machine learning-capable long-tail compute resources worldwide (such as small data centers and personal gaming computers), Gensyn can increase the available computational power for machine learning by 10 to 100 times.
In essence, Gensyn’s core mission is to democratize AI through blockchain initiatives.
In June 2023, Gensyn announced the completion of a $43 million Series A funding round led by a16z, with participation from CoinFund, Canonical Crypto, Protocol Labs, and Eden Block.
Gensyn was founded in 2020 by computer science and machine learning veterans Ben Fielding and Harry Grieve. Harry Grieve, a data scientist and entrepreneur, attended Brown University and the University of Aberdeen. Ben Fielding, a graduate of Northumbria University, co-founded the SaaS platform Fair Custodian and served as the director of Research Analytics.
TechFlow interviewed Gensyn co-founder Ben Fielding to learn about his journey in encrypted AI and Gensyn's AI initiatives.
What is Deep Learning? Deep learning is a branch of machine learning that focuses on training and using artificial neural networks (ANNs) with multiple layers to learn complex patterns and representations from data. Since 2023, ChatGPT has demonstrated how deep learning can significantly enhance labor productivity. In the AI race accelerated by tech giants like Google, Meta, and Microsoft, they aim to train their evolving AI systems by leveraging data. This has led to a 210.43% surge in Nvidia’s stock price over the past year, marking a strong demand for computational resources, the most quantifiable factor driving AI advancement due to algorithmic innovation, data, and computing power.
Since 2012, the computational demand for training deep learning models has increased by more than 300,000 times, doubling every 3.4 months, surpassing Moore’s Law’s doubling period of two years. This suggests that computation alone may not be sufficient to support the exponential growth of AI progress. Those stakeholders with the most computational resources may gain advantages, presenting risks of centralization. Various types of computational resources are available, each with its advantages and disadvantages.
According to the Gensyn Litepaper, the Gensyn Protocol is a trustless first-layer protocol for deep learning computations, which directly and immediately rewards the supply-side participants who commit computational time and perform machine learning tasks to the network. Compared to centralized cloud services, Gensyn aims to democratize computational resources by addressing significant complexities involved in renting out hardware for machine learning tasks, such as finding clients, establishing infrastructure and protocols, managing uptime, and potential financial liabilities, which are challenging for individuals or smaller entities.
After reviewing the Epicenter podcast and Gensyn Litepaper, we identified that a major challenge in developing the Gensyn Protocol is the need to find intersections between complexity theory, game theory, cryptography, and optimization to construct the protocol. Addressing these challenges, Gensyn’s co-founder Ben Fielding recently proposed a dual solution for the company. He elaborated on this innovative data availability layer and its contrast with Ethereum, and highlighted the greatest challenges in building Gensyn: ensuring the robustness of communication infrastructure, guaranteeing the reproducibility of machine learning runtime, and verifying large-scale off-chain, non-deterministic computations.
TechFlow: What's your story of founding Gensyn?
Ben:
My initial background was in academia, where I worked as a machine learning researcher focusing on Neural Architecture Search. This field involves optimizing the structure of deep neural networks, particularly for computer vision applications.
My approach involved developing algorithms to evolve neural network structures in a swarm-based manner. This process entailed training numerous candidate model architectures simultaneously and gradually evolving them into a single meta-model optimized for a specific task.
During this time, I encountered a significant challenge related to computing resources. As a PhD student, I had access to several high-performance GPUs located directly under my desk within large workstations I had managed to purchase.
Concurrently, entities like Google were conducting similar research but with thousands of GPUs and TPUs in data centers, running continuously for weeks. This disparity made me realize that despite having access to all necessary resources except adequate computing power, others around the world faced the same limitation, impeding the pace of research and societal progress. I found this situation unsatisfactory, which ultimately influenced much of Gensyn's current work.
Before fully committing to Gensyn, I spent two years co-founding a data privacy startup. This venture focused on managing consumer data flows and consent-based access to individual user data, aiming to improve how individuals and businesses interact regarding data.
The experience taught me valuable lessons, highlighted common startup pitfalls, and reinforced my cautious stance on individual data flows and consent-based access. These principles have partly shaped Gensyn's approach.
Four years ago, I closed my startup and joined an accelerator, Entrepreneur First, in London, where I met my co-founder, Harry Grieve. It was there that we initiated Gensyn, with the aim of addressing our computing challenges. Our initial strategy involved distributing compute tasks across private data silos within single organizations, which was intriguing. However, we quickly realized the broader potential of extending this approach globally. To tackle this expanded vision, we had to address fundamental trust issues related to the compute sources themselves.
Gensyn has since been dedicated to ensuring the accuracy of machine learning tasks processed on devices through a combination of proofs, game-theoretic incentive mechanisms, and probabilistic checks. While the specifics can become quite technical, Gensyn is committed to developing a system that enables anyone to use any computational device worldwide for training machine learning models.
TechFlow: Sam Altman wants $7 trillion to operate AI chip factories to take the challenge of global chip shortage problems. Is his plan realistic in terms of scaling chip supplies? Meanwhile, what specific problem is Gensyn tackling compared to Altman's solution?
Ben:
Regarding the AI space and the challenges it faces, Gensyn addresses a similar issue to what Sam Altman is tackling. Essentially, there are two ways to solve the problem of computing access. Machine learning is becoming increasingly ubiquitous, likely to be integrated into every piece of technology we use, moving from imperative code to probabilistic models. These models require vast amounts of computing power. When you compare the demand for compute with the world's ability to manufacture chips, you'll notice a significant divergence; demand is skyrocketing, while chip production is only gradually increasing.
The solution lies in either (1) manufacturing more chips to meet the demand or (2) enhancing the efficiency of existing chips' usage.
Ultimately, both strategies are necessary to address the growing demand for computing resources.
I think what Sam Altman has effectively done is confront the problem head-on. The issue lies in the chip supply chain, which is incredibly complex. Certain parts of this supply chain are particularly challenging, and only a handful of companies have the capability to manage these complexities. Currently, many governments are starting to view this as a geopolitical concern, investing in initiatives to relocate semiconductor fabrication plants domestically and address some of the bottlenecks within the supply chain.
What Sam Altman has proposed, in my view, is to test the market with the 7 trillion dollar figure, to gauge how critical the global financial markets perceive this problem to be. The lack of outright rejection of this staggering number has been fascinating. It prompted a collective reconsideration: 'That sounds absurd, but is it?'
This reaction indicates that there is indeed a significant concern and a willingness to allocate substantial funds to address it. By setting such a high benchmark, Altman has effectively created a reference point for any future efforts in chip production. This strategic move suggests that even if the actual cost doesn't reach 7 trillion dollars, it sets a precedent for substantial investment in this area, signaling a strong commitment to tackling the chip manufacturing challenge.
Our approach at Gensyn differs; we aim to optimize the use of existing chips across the globe. Many of these chips, found in devices ranging from gaming GPUs to Macbooks with M1, M2, M3 chips, remain underutilized.
They are perfectly capable of supporting AI processes without the need for developing new AI-specific processors. However, leveraging these existing resources requires a protocol that integrates them into a cohesive network, similar to how TCP/IP facilitates internet communication.
This protocol would enable on-demand access to these devices for computational tasks.
The key distinction between our protocol and traditional open-source protocols like TCP/IP lies in the financial aspect. While the latter are purely technological solutions, utilizing hardware resources involves inherent costs, such as electricity and the physical cost of the hardware itself.
To address this, our protocol incorporates cryptocurrency and decentralization principles to establish value flows, compensating hardware owners for their contribution.
Gensyn thus represents a dual-natured solution: it's both an open-source protocol for software connectivity and a financial mechanism for resource compensation.
Moreover, the challenges in the machine learning market extend beyond just compute resources.
Data access, knowledge sharing, and other factors also play critical roles. With decentralized technology, we can facilitate value attribution across these various components, promoting a more integrated and efficient ecosystem. In this way, Gensyn doesn't operate in isolation; we tackle part of the broader challenge, but it's essential for other solutions to address the remaining aspects. This collaborative effort is crucial for advancing the field of machine learning.
TechFlow: What is Gensyn's dual-natured solution in your simplest terms?
Ben:
In the simplest terms, Gensyn operates as a peer-to-peer network utilizing open-source software. If you possess a device capable of performing machine learning training tasks, running this software integrates your device into what's essentially a gossip network.
This network comprises nodes, each representing devices like yours, all operating the software without relying on a central server. Instead, devices communicate directly, sharing information about available hardware and tasks to be performed, ensuring proof of work completion.
A fundamental aspect of Gensyn is the absence of a centralized authority in this communication process. For instance, if you're using a MacBook, it connects and communicates with other MacBooks, exchanging information about hardware capabilities and available tasks. This direct interaction among devices circumvents the need for a central server.
For Gensyn, the challenge lies in verifying off-chain, non-deterministic computations that are too large for blockchain execution.
Our solution involves a verification mechanism that allows a device to produce a verifiable proof of the computation it has performed.
This proof can be checked by another device, ensuring the integrity of the work without revealing which portions of the task will be verified. This prevents devices from only completing parts of the task likely to be checked.
Our system facilitates a method where devices, acting as solvers and verifiers, engage in a cryptographic proof process or selective work rerun to establish the validity of the completed tasks.
This process culminates on the blockchain, confirming the task's successful execution to all nodes.
In essence, Gensyn is about nodes interoperating, verifying each other's work, and reaching consensus on completed tasks. Payments for tasks are executed within this framework, leveraging blockchain's trust mechanism.
This technical ecosystem mirrors Ethereum's functionality, focusing on mutual verification among nodes to ensure task integrity.
The primary goal is achieving consensus on task completion through minimal computational efforts, ensuring system integrity while accommodating large-scale machine learning tasks.
Gensyn can be divided into two main components.
The first half is the blockchain aspect, which includes the state machine I mentioned earlier. This is where the shared computations among participants occur.
The other half of Gensyn concerns the communication infrastructure, focusing on how the nodes interact with each other and handle machine learning tasks.
This setup allows any node to perform any computation, provided it can later verify the work on the blockchain side.
We're establishing a communication infrastructure that spans all nodes, facilitating information sharing, model splitting if necessary, and extensive data handling. This setup supports various model training methods, such as data parallelism, model parallelism, and pipeline partitioning, without the immediate need for trust coordination.
TechFlow: How does the Gensyn chain work for peer-2-peer compute contribution?
Ben:
Initially, it's assumed that all participants are fulfilling their roles and generating proofs. Then, attention shifts to the blockchain side, where we maintain a shared state akin to other blockchains, hashing transactions and operations, including hashing the previous block, which forms the chain.
The consensus among participants is that if the computations in a block match and produce the same hash, then the work is agreed upon as correctly done, allowing us to progress to the next block. This is where the rewards for producing blocks come into play.
Gensyn operates as a proof-of-stake blockchain, rewarding validators for their contribution to block production.
Creating a block involves (1) hashing the operations required for machine learning verification work (2) alongside the transactions that occurred within that block.
While our approach mirrors systems like Ethereum, our unique contributions primarily lie in the communication side, especially in how nodes manage and collaborate on machine learning tasks.
TechFlow: How is the Gensyn chain different from Ethereum? If the core infrastructure is not new, how was the POS chain designed to meet the specific use case of machine learning?
Ben:
Our blockchain's core structure isn't novel, with the exception of a novel data availability layer. The significant difference lies in our capacity to handle larger computational tasks, enabling more efficient operations than typically possible on Ethereum, given our freedom to conduct larger scale computations.
This is particularly relevant for convolution operations, a fundamental component of many machine learning models, which would be challenging to perform efficiently within the Ethereum Virtual Machine (EVM) using Solidity.
Gensyn's chain offers more flexibility, allowing us to handle these computations more effectively without being constrained by the limitations of the EVM's operational scope.
The real challenge lies in achieving the generalizability of a model: This means the model can encounter an entirely new sample and accurately predict where it fits, despite never having seen it before, because it understands the broader space sufficiently.
Such a training process demands enormous computational resources, as it involves repeatedly passing data through the model.
What Gensyn's machine learning runtime does is to take the graphical representation of a model and place it within a framework where, as computations are performed, we can generate proofs of each operation's completion.
A significant issue here is determinism and reproducibility.
Ideally, in a mathematical world, repeating an operation should yield identical results. However, in the physical world of computing hardware, unpredictable variables can lead to slight variations in computations.
Until now, a degree of randomness in machine learning has been acceptable, even beneficial, as it prevents models from overfitting and encourages better generalization.
Yet, for Gensyn, both generalizability and reproducibility are crucial.
Variability in computational outcomes can lead to entirely different hashes, potentially leading our verification system to incorrectly flag work as incomplete, risking financial loss. To counter this, our runtime ensures operations are deterministic and reproducible across devices, a complex but necessary solution.
This approach is somewhat analogous to using machine learning frameworks like PyTorch, TensorFlow, or JAX. Users can define models within these frameworks and initiate training. We are adapting these frameworks and the underlying libraries, such as Compute Unified Device Architecture (CUDA), to ensure that when a model is executed, it is done so in a reproducibly accurate manner across any device.
This guarantees that hashing the outcome of an operation on one device produces an identical hash on another, highlighting the importance of this aspect of machine learning execution in our system.
Addressing these fundamental challenges of determinism and reproducibility is vital, as the broader machine learning field does not typically solve these issues. You inquired about the machine learning training process, and I've provided a detailed explanation. I can also discuss the distribution and communication between models further if you're interested, or we can proceed to another topic if you prefer, recognizing that my response has been quite detailed.
TechFlow: Can you explain the communication infrastructure that facilitates management and collaboration in the machine learning context?
Ben:
The purpose of the communication infrastructure is to enable devices to communicate with each other. Primarily, it's used so that one device can verify the work and the proofs generated by another device.
Essentially, a device can communicate with another to have its work verified, but this process must go through the blockchain, which acts as the central arbitrator in any dispute. This is because the blockchain is our only source of trust within the system. Without it, there's no reliable way to confirm the identity of the parties involved; anyone could claim they've verified the work as a separate entity.
The blockchain, with its cryptographic mechanisms, allows for secure identity verification and confirmation of the work done. It enables devices to assert their identity and submit information securely, with other parties recognizing and validating this information as accurate.
The ultimate goal here is for device owners to be compensated. If you own hardware capable of performing machine learning tasks, you can rent it out.
However, in the current system, this is a complex and costly process. For example, purchasing a significant number of Nvidia GPUs as a capital expense and then renting them out—converting CapEx to OpEx, similar to cloud providers—entails numerous challenges. You need to find AI companies interested in your hardware, establish sales channels, develop infrastructure for model transfer and access, and manage legal and operational agreements including service level agreements (SLAs). These SLAs necessitate on-site engineering to ensure uptime, as agreed upon with your clients. Any downtime leads to direct accountability and potential financial liabilities based on the contracts. This complexity is a significant barrier for individuals or small entities, illustrating why centralized cloud services have become the norm. It's simply easier at scale than attempting to independently offer a few GPUs for rent, given all the infrastructure and agreements required.
What Gensyn offers is a significantly more efficient method because it eliminates the human and business costs typically involved in these transactions. Instead of relying on legal contracts and needing engineers to build infrastructure, you simply run some software, and it manages everything. Legal agreements are replaced with smart contracts, and the verification of work is done through a system that programmatically checks whether tasks were completed correctly. There's no need for the manual process of claiming breach of contract and seeking legal resolution. All of this can be settled instantly with technology, which is a profound advantage. It means suppliers can gain immediate returns on their GPUs just by running some software, without all the additional hassle.
This approach is how we encourage suppliers to join the Gensyn network. We're telling them they can instantly tap into the demand for machine learning compute by running open-source software. This is an unprecedented opportunity that significantly widens the market to new entrants, moving beyond the traditional dominance of services like AWS. AWS and others are required to manage complex operations, but we're converting those operations into code, creating new pathways for value flow.
Traditionally, if you had a machine learning model to train and were willing to pay for compute, your money would go to a major cloud provider who monopolizes the supply. They capture the market primarily because they are the few who can manage it efficiently. Despite increasing competition from Google Cloud, Azure, and others, the profit margins for these providers remain high.
TechFlow: Machine learning is broadly divided into training and inference. Which part is Gensyn's P2P compute resources taking a role in and why?
Ben:
Our focus is on training, which involves the distillation of value.
This encompasses everything from the initial learning to fine-tuning, whereas inference merely involves querying the model with data without altering it, essentially seeing what the model predicts based on the input.
Training demands significant computational resources and is typically asynchronous, not requiring immediate results.
In contrast, inference needs to be fast to ensure user satisfaction in real-time applications, presenting a distinct challenge from training's compute-intensive nature.
Decentralized technology, as it stands, isn't well-suited to addressing latency issues, which are critical for inference. Effective inference networks, potentially in the future, would need to deploy models as close to the user as possible, minimizing latency by leveraging proximity.
Bootstrapping such a network is challenging, given that its value and effectiveness grow with its size, a principle known as Metcalfe's Law, similar to the dynamics seen in networks like Helium.
Consequently, it wouldn't be practical for Gensyn to tackle the inference challenge directly; it would be better addressed by a separate entity focused on optimizing latency and network reach.
We subscribe to the thin protocol thesis, advocating for a protocol to excel in a singular function rather than diluting its effectiveness across multiple areas. This specialization fosters competition and innovation, leading to a network of interoperable protocols each mastering a specific aspect of the ecosystem.
Ideally, alongside running a Gensyn node for compute, users could operate nodes for inference, data management, and data labeling, among others. These interconnected networks would contribute to a robust ecosystem where the machine learning operation flows seamlessly across various platforms. This vision for a decentralized future promises a new layer of networks, each enhancing the capabilities of machine learning through collective contribution.
TechFlow: How does Gensyn's compute protocol collaborate with data protocol, considering compute and data are important inputs of machine learning?
Ben:
Compute is just one aspect; data is another significant area where the same value flow model can be applied, albeit with different verification and incentivization mechanisms.
Ultimately, we envision a rich ecosystem comprising multiple nodes running on devices like your MacBook. You might have a Gensyn compute node, a data node, or even a data labeling node on your device, contributing to data labeling through gamified incentives or direct payment, often without direct awareness of the behind-the-scenes processes contributing to these models.
This ecosystem paves the way for what we ambitiously call the machine intelligence revolution, signifying a new phase or evolution of the internet. The current internet serves as a vast repository of human knowledge in text form.
We envision the future of the internet in an embedding space, represented through machine learning models rather than text. This means having fragments of machine learning models distributed across devices worldwide, from MacBooks to iPhones and cloud servers, enabling us to perform queries through inference across this distributed network. This model promises a more open ecosystem compared to the centralized model dominated by a few cloud providers, facilitated by blockchain technology.
Blockchain not only incentivizes the sharing of resources but also ensures instantaneous verification, confirming that tasks performed by remote devices are executed correctly and not fabricated.
Gensyn is focused on developing the compute primitive within this framework, and we encourage others to explore additional aspects, such as incentivized data networks. Ideally, Gensyn would integrate seamlessly with these networks, enhancing the efficiency of machine learning training and usage. Our goal isn't to monopolize the entire machine learning stack but to establish Gensyn as a protocol that optimizes the use of compute resources, positioned just above electricity, to significantly improve humanity's capacity to utilize its computational assets more effectively.
Gensyn specifically addresses the challenge of converting value and data into the parameters of a model. Essentially, if you possess a data sample – be it an image, a book, some text, audio, or video – and you wish to compress that data into model parameters, Gensyn facilitates this process. This enables the model to make predictions or inferences about similar data in the future as you update those parameters. The entire process of distilling data into model parameters is Gensyn's domain, while other aspects of the machine learning stack are managed elsewhere.
TechFlow: Given your extensive experience, could you compare the early days of being a builder and researcher in the tech field—dealing with the frustrations and challenges of computing and technology—to your current experiences? Specifically, I'm interested in how the tech environment in London has influenced your work and outlook. Could you share your insights on this transition and the impact of the London tech culture on your development and achievements?
Ben:
The landscape in London, and broadly in the UK, is distinctively different, particularly when compared to Silicon Valley. The UK’s tech community, though brimming with exceptional talent and groundbreaking work, tends to be more insular. This creates a barrier for newcomers trying to integrate into these circles.
The difference, I believe, stems from a contrast in attitudes between Britain and the US. Americans generally exhibit a more open demeanor, whereas Britons are typically more skeptical and reserved. This cultural nuance means that it takes effort and time to navigate and assimilate into the UK's tech ecosystem. However, once you do, you discover an incredibly vibrant and rich community engaged in fascinating projects. The difference is in visibility and outreach; unlike in Silicon Valley where achievements are loudly celebrated, London's innovators tend to work more quietly.
Recently, the UK, particularly with the shift towards decentralization and AI, seems to be carving out a niche for itself. This is in part due to regulatory developments in the US and Europe. For instance, recent US regulations, such as those outlined in President Biden's executive order, impose certain restrictions on AI development, including mandatory government reporting for projects exceeding specific thresholds. These regulations can dampen the enthusiasm of new developers. In contrast, the UK appears to be adopting a more open stance, favoring open source over stringent regulation, thus fostering a more conducive environment for innovation.
San Francisco, known for its robust open-source movement, faces new challenges with California’s legislation mirroring the federal executive order. Such regulations, despite their good intentions of safeguarding society, inadvertently consolidate AI development within established entities. These entities have the means to comply with regulatory demands, whereas smaller players, with potentially revolutionary ideas, find themselves at a disadvantage. The UK recognizes the value of open source as a means of societal oversight on AI development, bypassing the need for restrictive governmental monitoring. Open-source practices naturally facilitate scrutiny and collaboration, ensuring that AI technologies remain in check without stifling innovation.
The EU's initial approach to AI regulation was more stringent than what we've seen from the UK, which has managed to strike a balance that encourages open source development. This strategy not only aims to achieve the same regulatory goals but also ensures the market remains vibrant and competitive. The UK’s positioning is particularly advantageous for fostering a dynamic and open ecosystem for AI and crypto innovations. It's an exciting time for the tech industry in London.




Recommendation
Dialogue with Klaytn Foundation Director on Koreas Web3 Nautical Map
Jun 06, 2024 13:21
Interview with Lukas Schor: Call me Safe not Gnosis Safe
Jun 06, 2024 22:54
Dialogue with Near Co-Founder: From AI Guru to Founder of A Public Blockchain, the Worldview of Illia in AI and Cryptography
Jun 06, 2024 23:11
 Original link
Original link